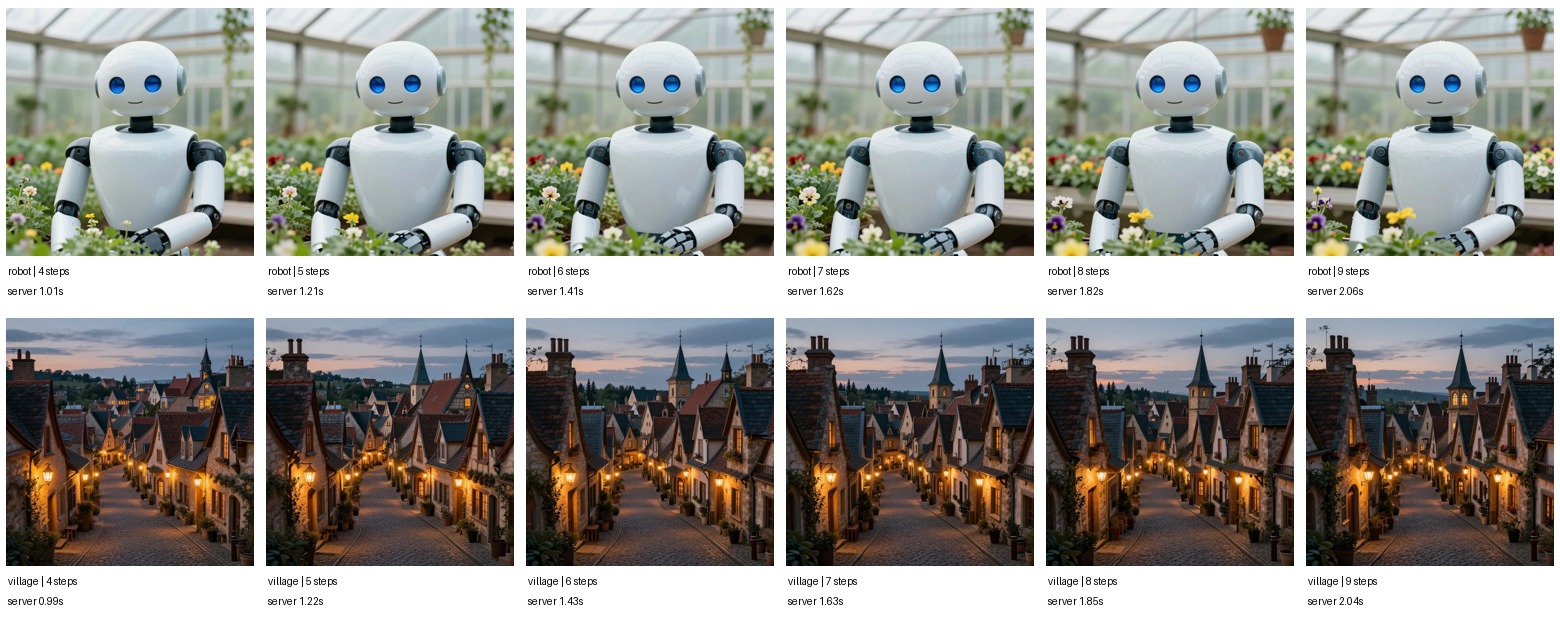
Step Count Sweep
4, 6, 8, 9, 10, 12, 16, 20 steps
Choice
8 steps
Observed
Best quality/time knee. 4-6 are fast but visibly thinner; 12+ adds little for normal prompts.
Try next: Try 6 steps for drafts, 8 for production, 12 only when detail is visibly missing.